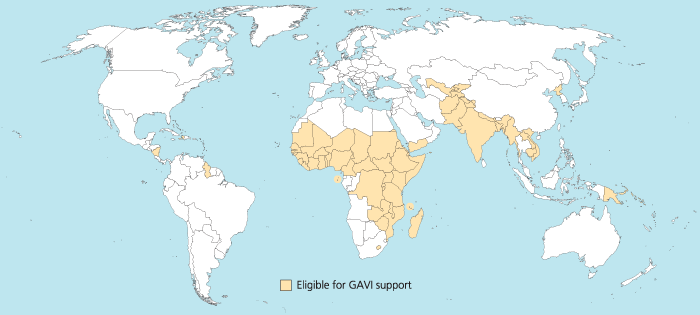
I was trying to reproduce the map of the GAVI Alliance eligible countries (btw I was surprised India is eligible – but that’s the beauty of relying on numbers only and not assumptions) in R. This is the original map (there are 57 countries eligible):
I started to use the R package rworldmap because it seemed the most appropriate for this task. Everything went fine. Most of the time was spent converting the list of countries from plain English to plain “ISO3” code as required (ISO3 is in fact ISO 3166-1 alpha-3). I took my source from Wikipedia.
Well, that was until joinCountryData2Map gave me this reply:
54 codes from your data successfully matched countries in the map
3 codes from your data failed to match with a country code in the map
189 codes from the map weren’t represented in your data
I should have better simply read the documentation: there is another small command that needs not to be overlooked, rwmGetISO3. What are the three codes that failed to match?
Although you can compare visually the map produced with the map above, R (and rworldmap) can indirectly give you the culprits:
tC2 = matrix(c("Afghanistan", "Bangladesh", "Benin", "Burkina Faso", "Burundi", "Cambodia", "Cameroon", "Central African Republic", "Chad", "Comoros", "Congo, Dem Republic of", "Côte d'Ivoire", "Djibouti", "Eritrea", "Ethiopia", "Gambia", "Ghana", "Guinea", "Guinea Bissau", "Haiti", "India", "Kenya", "Korea, DPR", "Kyrgyz Republic", "Lao PDR", "Lesotho", "Liberia", "Madagascar", "Malawi", "Mali", "Mauritania", "Mozambique", "Myanmar", "Nepal", "Nicaragua", "Niger", "Nigeria", "Pakistan", "Papua New Guinea", "Rwanda", "São Tomé e Príncipe", "Senegal", "Sierra Leone", "Solomon Islands", "Somalia", "Republic of Sudan", "South Sudan", "Tajikistan", "Tanzania", "Timor Leste", "Togo", "Uganda", "Uzbekistan", "Viet Nam", "Yemen", "Zambia", "Zimbabwe"), nrow=57, ncol=1)
apply(tC2, 1, rwmGetISO3)
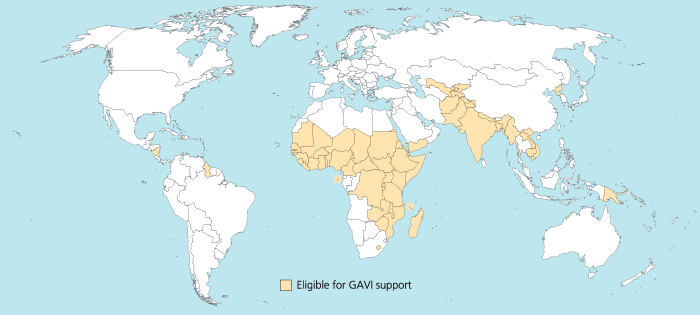
In the results, some countries are actually given in a slightly different way by GAVI than in R. For instance “Congo, Dem Republic of” should be changed for rworldmap in “Democratic Republic of the Congo” (ISO3 code: COD). Or “Côte d’Ivoire” should be changed for rworldmap in “Ivory Coast” (ISO3 code: CIV). An interesting resource for country names recognised by rworld map is the UN Countries or areas, codes and abbreviations. Once you correct this, you can have your map of GAVI-eligible countries:

And here is the code:
# Displays map of GAVI countries
library(rworldmap)
theCountries <- c("AFG", "BGD", "BEN", "BFA", "BDI", "KHM", "CMR", "CAF", "TCD", "COM", "COD", "CIV", "DJI", "ERI", "ETH", "GMB", "GHA", "GIN", "GNB", "HTI", "IND", "KEN", "PRK", "KGZ", "LAO", "LSO", "LBR", "MDG", "MWI", "MLI", "MRT", "MOZ", "MMR", "NPL", "NIC", "NER", "NGA", "PAK", "PNG", "RWA", "STP", "SEN", "SLE", "SLB", "SOM", "SDN", "SSD", "TJK", "TZA", "TLS", "TGO", "UGA", "UZB", "VNM", "YEM", "ZMB", "ZWE")
GaviEligibleDF <- data.frame(country = c("AFG", "BGD", "BEN", "BFA", "BDI", "KHM", "CMR", "CAF", "TCD", "COM", "COD", "CIV", "DJI", "ERI", "ETH", "GMB", "GHA", "GIN", "GNB", "HTI", "IND", "KEN", "PRK", "KGZ", "LAO", "LSO", "LBR", "MDG", "MWI", "MLI", "MRT", "MOZ", "MMR", "NPL", "NIC", "NER", "NGA", "PAK", "PNG", "RWA", "STP", "SEN", "SLE", "SLB", "SOM", "SDN", "SSD", "TJK", "TZA", "TLS", "TGO", "UGA", "UZB", "VNM", "YEM", "ZMB", "ZWE"),
GAVIeligible = c(1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1))
GAVIeligibleMap <- joinCountryData2Map(GaviEligibleDF, joinCode = "ISO3", nameJoinColumn = "country") mapCountryData(GAVIeligibleMap, nameColumnToPlot="GAVIeligible", catMethod = "categorical", missingCountryCol = gray(.8))